Plan Disaster Recovery (DRP) i BCP – jak przygotować firmę na utratę systemów

W erze zaawansowanej cyfryzacji oraz nowych wymagań regulacyjnych (np. NIS2), ciągłość działania systemów IT stała się kluczowym elementem zarządzania ryzykiem operacyjnym w każdym stabilnym biznesie. Przerwy wywołane awariami infrastruktury, błędami ludzkimi czy cyberatakami (np. ransomware) to aktualnie realne scenariusze, na które organizacja musi być przygotowana. Firma musi być krok przed atakującymi i być gotowa na najgorszy scenariusz, w czym pomaga BCP (Business Continuity Plan).
Wielu menedżerów oraz działów IT nadal utożsamia odporność biznesową (cyber resilience) z poprawnie skonfigurowaną procedurą tworzenia kopii zapasowych. To fundamentalny błąd, ponieważ sam backup jest jedynie statycznym zabezpieczeniem danych – wynikiem, a nie procesem. Bez precyzyjnie zdefiniowanych procedur odtwarzania, podziału odpowiedzialności oraz wskaźników tolerancji strat, organizacja w momencie kryzysu staje w obliczu paraliżu operacyjnego.
Budowa skutecznej odporności wymaga wdrożenia dwóch strategii: Business Continuity Plan (BCP), który zabezpiecza kluczowe procesy biznesowe na poziomie całej organizacji, oraz Disaster Recovery Plan (DRP), stanowiący techniczny fundament odtworzenia infrastruktury IT.
Iluzja bezpieczeństwa, czyli dlaczego zwykłe backupy to za mało
Większość organizacji deklaruje, że posiada zaawansowane zabezpieczenia przed utratą danych. Najczęstszą odpowiedzią na pytanie o gotowość awaryjną jest stwierdzenie: „Tak, procedury są wdrożone, a backupy wykonują się codziennie”. Niestety, w warunkach prawdziwego kryzysu ta deklaracja bardzo często okazuje się początkiem paraliżu operacyjnego. Takie podejście wynika zazwyczaj z braku rozróżnienia mechanizmu retencji danych (ich przechowywania) z procesem zapewnienia ciągłości dostępu do nich. Sam fakt posiadania kopii zapasowej w chmurze nie gwarantuje, że w razie awarii fizycznego środowiska, zostanie ono bezbłędnie odtworzone. Takie prowadzi do miejsca, w którym nie mamy kopii zapasowej, a „kopię zapasową”, czyli uszkodzoną kopię zapasową, która nie ma żadnej wartości.
W praktyce, bez wdrożonego i sformalizowanego planu DRP, organizacje w momencie incydentu zderzają się z następującymi przeszkodami:
- Brak weryfikacji integralności aplikacji – Kopie zapasowe są wykonywane automatycznie, ale systemy monitoringu sprawdzają jedynie status zakończenia zadania. Faktyczny stan i kondycja logiczna kopii nadal pozostaje nieznana. W krytycznym momencie okazuje się, że backup zawiera uszkodzone tabele bazy danych lub zaszyfrowane pliki przez niewykryte oprogramowanie typu ransomware.
- Ignorowanie zależności międzysystemowych – Współczesne systemy klasy ERP, CRM czy platformy analityczne potrzebują danych z różnych źródeł. Wymagają wcześniejszego, poprawnego uruchomienia usług infrastrukturalnych: kontrolerów domeny (Active Directory / LDAP), serwerów DNS, systemów uwierzytelniania sieciowego oraz baz danych. Próba uruchomienia aplikacji biznesowej przed podniesieniem niezbędnych usług i sieci może skutkować szeregiem błędów, które mogą opóźnić powrót do operacyjności.
- Brakujące zasoby w infrastrukturze – Organizacja może dysponować poprawnym backupem o niemałym wolumenie, np. 10 TB. W momencie katastrofy okazuje się, że przepustowość łącza WAN do chmury (na której przechowywane są backupy) lub wydajność operacji wejścia/wyjścia (IOPS) dysków docelowych pozwala na odtwarzanie danych z prędkością, która rozciąga proces przywracania systemów na wiele dni lub tygodni.
- Chaos decyzyjny i stres – Podczas incydentu o wysokim priorytecie, zespół IT działa pod wpływem ekstremalnego stresu i presji zarządu. Bez precyzyjnych i aktualnych instrukcji technicznych, zespół nie wie jak ma działać i zaczynają popełniać błędy. Pojawia się chaos komunikacyjny, ponieważ nie wiadomo, kto podejmuje decyzję o rekonfiguracji środowiska i dalszych działaniach.
W efekcie samo posiadanie backupu bez kompletnej i przetestowanej procedury Disaster Recovery stanowi jedynie iluzję ochrony. Można to porównać do sytuacji, w której mamy koło zapasowe w samochodzie, ale nie mamy przy sobie narzędzi potrzebnych do jego założenia.

Chcesz sprawdzić, czy Twoje procedury są gotowe na kryzys?
Nie czekaj na incydent, aby zweryfikować sprawność swoich systemów. Sprawdź naszą checklistę, która pozwoli Ci samodzielnie ocenić poziom odporności Twojej infrastruktury oraz zidentyfikować potencjalne braki i niejasności w procesach odtwarzania danych.
Konsekwencje biznesowe utraty dostępności systemów
Ignorowanie ryzyka związanego z niedostępnością systemów IT to bezpośrednie wystawienie organizacji na straty finansowe, operacyjne oraz wizerunkowe. Współczesne organizacje są tak zależne od własnej infrastruktury, że jej paraliż lub utrata danych natychmiast przekładają się na zatrzymanie procesów biznesowych na każdym szczeblu. Konsekwencje takich przerw mogą być dotkliwe na wielu różnych płaszczyznach:
1. Straty finansowe i operacyjne
- Bezpośrednia utrata przychodów – W sektorach takich jak e-commerce, niedostępność platformy sprzedażowej to brak konwersji i ucieczka klientów do konkurencji.
- Koszty bezczynności operacyjnej – Mimo paraliżu systemów ERP, firma nadal ponosi koszty stałe, np. wynagrodzenia pracowników, którzy nie mogą pracować z powodu braku dostępu do usług.
- Kary umowne i naruszenia umów SLA – Niedotrzymanie terminów dostaw czy brak ciągłości działania skutkuje naliczaniem kar finansowych.
2. Skutki prawne i regulacyjne
W obecnym otoczeniu regulacyjnym niedostępność systemów nie jest traktowana jedynie jako problem wewnętrzny firmy, ale jako potencjalne naruszenie przepisów prawa.
- Kary administracyjne (RODO / GDPR) – Jeśli utracie dostępności systemów towarzyszył wyciek lub naruszenie bezpieczeństwa danych osobowych, organy nadzorcze (np. UODO) mogą nałożyć kary sięgające do 20 milionów euro lub 4% globalnego rocznego obrotu przedsiębiorstwa.
- Dyrektywa NIS 2 i DORA – Podmioty kluczowe i ważne (np. energetyczne) są prawnie zobligowane do zapewnienia ciągłości działania. Brak wdrożonych planów BCP/DRP wiąże się z osobistą odpowiedzialnością finansową i dyscyplinarną kadry zarządzającej oraz wielomilionowymi sankcjami dla samej organizacji.
3. Straty wizerunkowe i utrata zaufania rynkowego
O ile straty finansowe można odrobić, o tyle odbudowa reputacji po poważnym incydencie trwa latami. Czasami skala incydentu jest na tyle dotkliwa, że firma może już nie powrócić na rynek.
- Naruszenie zaufania klientów – Informacja o długotrwałej awarii lub udanym ataku ransomware błyskawicznie przedostaje się do mediów i partnerów biznesowych. Klienci tracą poczucie bezpieczeństwa powierzanych firmie danych i kapitału.
- Spadek wartości rynkowej – W przypadku spółek giełdowych, przedłużający się kryzys IT wywołuje natychmiastową reakcję inwestorów i gwałtowny spadek wyceny.
Koszt zaprojektowania i utrzymania profesjonalnego planu Disaster Recovery stanowi ułamek wydatków, jakie organizacja musi ponieść na pokrycie strat wynikających z zaledwie jednego dnia paraliżu systemów produkcyjnych. DRP jest inwestycją w przetrwanie biznesu.
Dlaczego standardowe podejście do ciągłości działania nie działa?
Tradycyjne podejście do bezpieczeństwa IT, opierało się na architekturze reaktywnej, czyli gdy powstanie awaria, administrator ją usunie. Mając na uwadze obecne cyberzagrożenia, ten model zarządzania incydentami staje się bezpośrednią przyczyną porażki. Istnieje kilka kluczowych powodów, dla których standardowe, intuicyjne metody ochrony zawodzą w starciu z prawdziwą katastrofą.
1. Traktowanie DRP jako projektu wyłącznie technologicznego
Najczęstszym błędem jest delegowanie całkowitej odpowiedzialności za ciągłość działania na dział IT. Jeśli zespół sam decyduje, które serwery są najważniejsze, robią to z perspektywy technicznej, a nie biznesowej, która generuje zysk. Bez ścisłej współpracy, IT nie jest w stanie prawidłowo uszeregować priorytetów odtwarzania maszyn wirtualnych czy usług bazodanowych.
2. Bezwarunkowa wiara w lokalną redundancję
Wielu administratorów uważa, że posiadanie macierzy dyskowej (RAID), klastrów wysokiej dostępności (HA) lub replikacji danych eliminuje potrzebę posiadania planu DRP. To niebezpieczne uproszczenie prowadzące do dotkliwej utraty kontroli nad własną infrastrukturą.
- Klastry HA i RAID chronią jedynie przed awariami sprzętowymi (np. uszkodzeniem jednego zasilacza lub dysku).
- Synchroniczna replikacja danych natychmiastowo przenosi każdy błąd logiczny. Jeśli ransomware zacznie szyfrować pliki w głównej lokalizacji, zreplikowane środowisko w ułamku sekundy otrzyma zaszyfrowane dane. Ponadto lokalna redundancja staje się bezużyteczna w przypadku zdarzeń losowych, takich jak pożar, zalanie budynku czy całkowity blackout regionalny.
3. Statyczność procedur
Plan DRP bardzo często powstaje jako teoretyczna formalność – np. w celu przejścia audytu certyfikującego ISO 27001 lub spełnienia wymogów ubezpieczyciela. Taki dokument trafia potem do szuflady i jego cykl życia dobiega końca. Infrastruktura IT dynamicznie się zmienia – nowe serwery, modyfikowane są adresy IP, wdrażane są aktualizacje systemów ERP, zmienia się personel. Plan DRP nietestowany i nieaktualizowany przez sześć miesięcy może się okazać nieskuteczny w momencie, kiedy będzie trzeba go wdrożyć.
4. Brak uwzględnienia czynnika ludzkiego i psychologicznego
Standardowe podejście zakłada, że w momencie awarii cały zespół IT będzie działał z takim samym spokojem, jak podczas codziennych zadań. W warunkach rzeczywistego kryzysu – przy braku precyzyjnych scenariuszy – kluczowi pracownicy ulegają presji. Pojawia się problem niedostępności personelu (np. incydent wydarza się w nocy), a bez zaplanowanego zastępstwa, proces decyzyjny ulega paraliżowi.
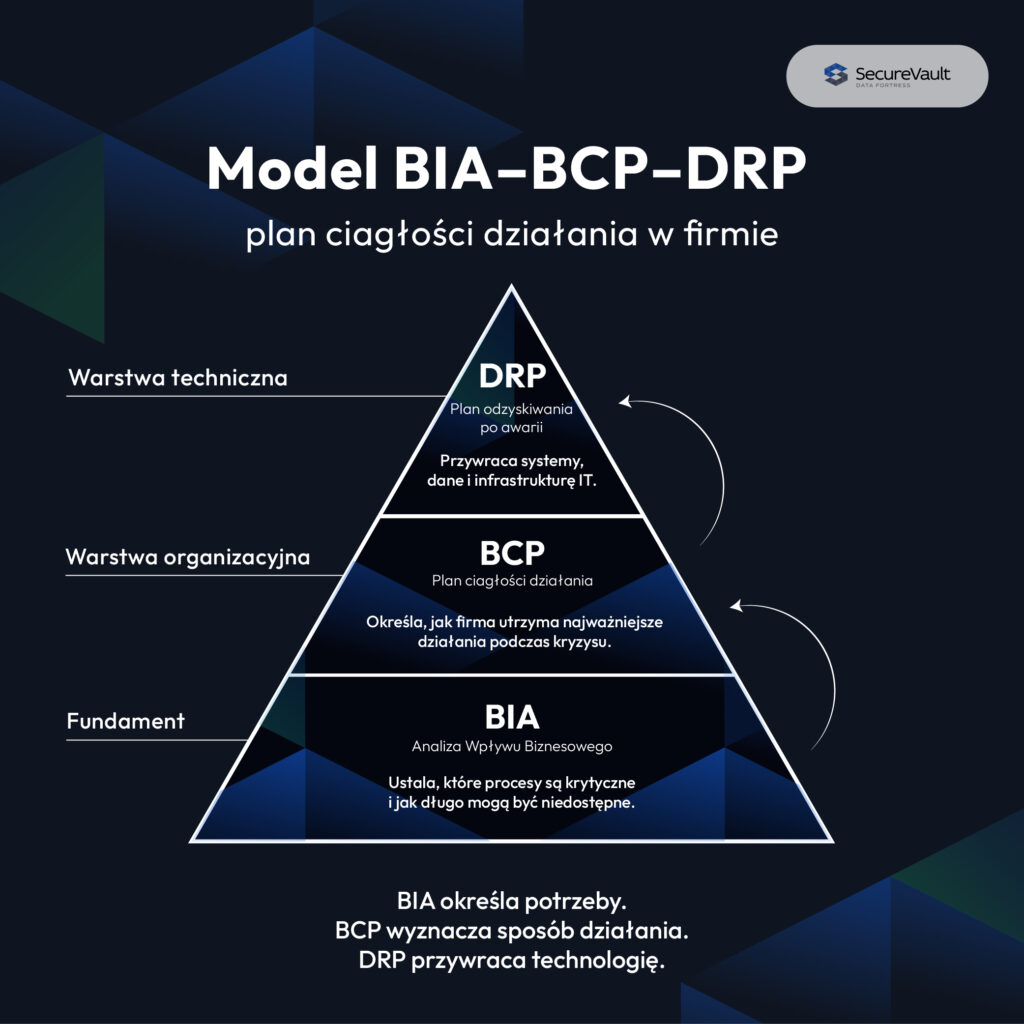
Model referencyjny: BCP i DRP w strukturze organizacyjnej
Skuteczne zarządzanie ciągłością działania wymaga precyzyjnego umiejscowienia poszczególnych procedur w strukturze organizacyjnej firmy. BCP i DRP stanowią elementy spójnego, warstwowego modelu referencyjnego, który określa wymagania biznesowe na konkretne działania techniczne.
W profesjonalnej architekturze bezpieczeństwa model ten opiera się na trzech ściśle powiązanych ze sobą poziomach:
1. Fundament: BIA (Business Impact Analysis)
Analiza Wpływu Biznesowego (BIA) to punkt wyjścia dla jakichkolwiek działań strategicznych. Jest to proces audytowy, którego celem jest identyfikacja krytycznych procesów biznesowych oraz oszacowanie skutków ich finansowej i operacyjnej niedostępności w czasie. To podczas fazy BIA wyznaczane są kluczowe wskaźniki tolerancji strat dla poszczególnych systemów, które determinują dalsze inwestycje w infrastrukturę IT.
2. Warstwa Makro: BCP (Business Continuity Plan)
Plan ciągłości działania to strategia nadrzędna i zarządzana z poziomu Zarządu lub dedykowanego Komitetu Kryzysowego. BCP koncentruje się na firmie jako całości i odpowiada na pytanie: „Jak utrzymać funkcjonowanie biznesu, gdy podstawowe zasoby są niedostępne?”. W zakresie tej warstwy jest wyznaczenie alternatywnego miejsca pracy dla personelu, łańcucha dostaw, aspektów prawnych oraz planu komunikacji kryzysowej.
3. Warstwa Mikro / Techniczna: DRP (Disaster Recovery Plan)
Plan odtwarzania po katastrofie jest bezpośrednim komponentem wykonawczym wchodzącym w skład BCP, w całości delegowanym do działu IT i cyberbezpieczeństwa. DRP odpowiada na pytanie: „Jak przywrócić sprawność naszej infrastruktury do stanu zdefiniowanego w BIA?”. Skupia się na warstwie technicznej – odtworzeniu sieci LAN/WAN, przywrócenia baz danych, konfigurację replikacji maszyn wirtualnych oraz przywróceniu sprawności systemów końcowych.
Hierarchia uruchamiania procedur w momencie incydentu:
- Detekcja i Eskalacja – Systemy monitoringu (SIEM/SOC) lub personel identyfikują anomalie/katastrofę.
- Aktywacja BCP – Sztab kryzysowy przejmuje zarządzanie organizacją, uruchamia procedury i zabezpiecza ciągłość procesów biznesowych.
- Egzekucja DRP – Zespół IT, działając według ścisłych instrukcji DRP, rozpoczyna oczyszczanie infrastruktury po ataku i rekonstrukcję środowiska produkcyjnego.
Architektura odporności: Nowoczesny standard Disaster Recovery
Aby zminimalizować wskaźniki RTO i RPO do poziomów wymaganych przez współczesny biznes, architektura systemowa nie może opierać się na tradycyjnych, podatnych na modyfikacje udziałach sieciowych. Poniższy model referencyjny pokazuje, jak wygląda profesjonalnie zaprojektowany plan zabezpieczania i separacji danych, odporny na najtrudniejszy scenariusz – w tym bezpośredni atak ransomware na infrastrukturę produkcyjną:
Analiza kluczowych komponentów schematu:
- Warstwa produkcyjna (Primary Data): Serwery fizyczne oraz maszyny wirtualne działające w podstawowej lokalizacji. Są one głównym celem ataków i awarii sprzętowych, dlatego stanowią punkt wyjścia dla systemów replikacji.
- Centralizacja procesu (Backup Server): Dedykowany, odizolowany serwer zarządzający (np. Veeam Backup Server), który orkiestruje zadania transferu danych, weryfikuje ich spójność logiczną oraz nadzoruje polityki retencji.
- Repozytorium niezmienne (Immutable Backup / WORM): Kluczowy element obrony przed cyberatakami. Wykorzystanie technologii Write-Once-Read-Many oznacza, że raz zapisane dane zostają zablokowane i stają się odporne na próby usunięcia lub modyfikacji. Nawet w przypadku przejęcia najwyższych uprawnień administratora domeny w sieci produkcyjnej, cyberprzestępca nie ma technicznej możliwości usunięcia, zmodyfikowania ani zaszyfrowania tych kopii przed upływem zdefiniowanego czasu blokady.
- Separacja fizyczna (Air-Gapped & Disaster Recovery Site): Przesyłanie zweryfikowanych migawek systemowych do zewnętrznego, fizycznie odseparowanego centrum danych (DR Site). Zapewnia to pełną niezależność operacyjną w scenariuszach katastroficznych (blackout, pożar, zalanie) i pozwala na natychmiastowe uruchomienie maszyn wirtualnych w infrastrukturze zapasowej.
Case Study: Paraliż firmy produkcyjnej wskutek ataku ransomware
Aby zobrazować teoretyczne założenia, przeanalizujmy przypadek przedsiębiorstwa produkcyjnego. Firma zatrudnia około 350 pracowników oraz posiada rozproszoną strukturę: centralę, dwa zakłady produkcyjne oraz trzy magazyny logistyczne.
Stan wyjściowy (Infrastruktura i procedury)
Firma posiadała zintegrowany system klasy ERP zarządzający produkcją, zamówieniami i fakturowaniem, osadzony na klastrze bazodanowym MS SQL Server w lokalnej serwerowni. Architektura bezpieczeństwa opierała się na klasycznym firewallu brzegowym, oprogramowaniu antywirusowym na stacjach końcowych oraz codziennym backupie wykonywanym na lokalny serwer NAS za pomocą standardowych udziałów sieciowych SMB. Zarząd nie widział potrzeby inwestycji w audyt BIA ani formalny plan DRP, argumentując, że „skoro kopie zapasowe wykonują się automatycznie każdej nocy, to firma jest w pełni bezpieczna”.
Przebieg incydentu
- Infiltracja: W nocy z piątku na sobotę doszło do kompromitacji sieci wewnętrznej poprzez ukierunkowany atak phishingowy na konto pracownika działu logistyki. Napastnicy wykorzystali luki w konfiguracji uprawnień lokalnych i przeprowadzili eskalację, uzyskując dostęp do konta z uprawnieniami administratora.
- Lateral Movement i rekonesans: Przez kolejne 48 godzin przestępcy mapowali topologię sieci, identyfikując kluczowe zasoby: serwery produkcyjne ERP, kontrolery domeny Active Directory oraz serwer NAS z kopiami zapasowymi.
- Destrukcja: W niedzielę o godzinie 2:00 rano uruchomiono skrypt szyfrujący ransomware. W pierwszej kolejności zaatakowano serwer NAS – napastnicy z poziomu skompromitowanego konta administratora usunęli wszystkie historyczne punkty przywracania oraz pliki kopii zapasowych. Następnie zaszyfrowano bazy produkcyjne ERP oraz maszyny wirtualne na hypervisorach.
Skutki braku procedur DRP i BCP
W poniedziałek o godzinie 6:00 rano, wraz z początkiem pierwszej zmiany, firma stanęła w obliczu całkowitego paraliżu operacyjnego. Brak precyzyjnych procedur awaryjnych wywołał natychmiastowe konsekwencje:
- Chaos decyzyjny: Zespół IT podjął intuicyjną, nieskoordynowaną próbę restartowania serwerów i losowego przywracania maszyn, co doprowadziło do nadpisania logów systemowych i utrudniło późniejszą analizę śledczą. Potencjalna szansa na znalezienie luki bezpieczeństwa, która była wektorem ataku, właśnie przestała istnieć.
- Brak punktu odniesienia: Po zalogowaniu się na serwer NAS zespół odkrył, że wszystkie backupy zostały bezpowrotnie zniszczone. Udział sieciowy SMB nie posiadał żadnych zabezpieczeń typu Immutable ani separacji logicznej.
- Zatrzymanie logistyki i produkcji: Magazyny nie mogły wydawać towarów (brak dostępu do systemów), a linie produkcyjne zostały zatrzymane z powodu braku specyfikacji technicznych zamówień.
- Koszty finansowe: Całkowity przestój operacyjny trwał 11 dni. Koszt odtworzenia struktury IT od zera przy pomocy zewnętrznych specjalistów, kary umowne za niedotrzymanie terminów dostaw do kontrahentów oraz straty operacyjne wyniosły łącznie ponad 2,2 miliona złotych. Zaufanie dwóch strategicznych partnerów biznesowych zostało trwale nadszarpnięte, a część kontrahentów podjęła współpracę z firmą konkurencyjną.
Wnioski i wdrożone środki naprawcze
Po zażegnaniu kryzysu zarząd podjął decyzję o całkowitej restrukturyzacji podejścia do ciągłości działania. Wdrożono profesjonalną architekturę opartą na standardach, które wcześniej ignorowano:
- Przeprowadzono pełną analizę BIA i zdefiniowano twarde wskaźniki; RTO na poziomie 8 godzin oraz RPO na poziomie 2 godzin dla systemu ERP. Został też opracowany BCP, jest on znany pracownikom i regularnie aktualizowany przez zarząd.
- Wdrożono dedykowane repozytorium Immutable Backup z blokadą czasową (WORM) na poziomie systemu plików, całkowicie odizolowane od produkcyjnej domeny Active Directory.
- Wydzielono część budżetu firmy na utrzymanie zapasowego środowiska w chmurze wraz z ciągłą replikacją asynchroniczną maszyn krytycznych.
- Wprowadzono obligatoryjne, cykliczne testy scenariuszowe DRP, sprawdzające zdolność zespołu IT do pełnego podniesienia systemów w odizolowanym środowisku testowym.
Chcesz sprawdzić, czy Twoje procedury są gotowe na kryzys?
Nie czekaj na incydent, aby zweryfikować sprawność swoich systemów. Sprawdź naszą checklistę, która pozwoli Ci samodzielnie ocenić poziom odporności Twojej infrastruktury oraz zidentyfikować potencjalne braki i niejasności w procesach odtwarzania danych.
Najczęściej zadawane pytania (FAQ)
Dowiedz się więcej
Jak wygląda test odtworzeniowy w praktyce – case study Disaster Recovery
Backup offsite w NIS2 – dlaczego backup w tej samej infrastrukturze to nie backup
DRaaS w firmie (Disaster Recovery as a Service) – dlaczego firmy potrzebują środowiska zapasowego?
RTO i RPO w NIS2 – jak je ustalić i dlaczego większość firm robi to źle
Zobacz również





Nie wiesz który pakiet jest odpowiedni dla twojej firmy?
Wypełnij krótką ankietę
Wypełnij krótki formularz, a pomożemy Ci wybrać rozwiązanie, które realnie
ochroni Twoją firmę i zapewni jej ciągłość działania nawet w przypadku awarii.